Zero-Server Image Editing:The Future of Bulk Image Processing Speed and Privacy
Built for developers, by developers. Experience the power of recursive image pipelines directly in your browser.
Beyond Serverless: The Rise of "No-Server" Architecture
For years, the gold standard for image optimization was the "Cloud API" model. You’d integrate Cloudinary, Imgix, or a custom AWS Lambda function. While powerful, these solutions share three fatal flaws: high latency from data round-trips, ballooning subscription costs, and the unavoidable risk of exposing private user data on external disks.
I learned this the hard way back in June 2025. I was handling a batch of 200 sensitive architectural photos for a client. I used a well-known cloud converter, only to have the server glitch halfway through the 400MB upload. Not only did the process fail, but my original queue vanished, and I spent the next week seeing targeted ads that suspiciously matched the content of those private files. That was the "Aha!" moment: the cloud isn't just a convenience; it’s a security hole we’ve been trained to ignore.
In 2026, we are witnessing a paradigm shift. We aren't just moving the logic to the "Edge"; we are moving it to the Client. With Bulk Image Editor, we’ve pioneered a Zero-Server architecture. By combining the static delivery power of Nuxt SSG with the raw performance of WebAssembly, we’ve built a system where the "Server" is nothing more than a delivery mechanism for code. The actual workstation? That's your browser.
A Rant: Why is "Simple" Image Editing so Broken?
Before we dive into the tech, can we talk about the state of "online tools"? You search for a simple resizer, click a promising link, and BAM—a popup demands you create an account. You provide your email, wait for a verification code that never arrives, and when you finally get in, you're hit with a "Premium Only" watermark or forced to watch a 30-second ad for a mobile game just to download a 100KB file.
It is exhausting, disrespectful, and predatory. At BulkPicTools, we have a simple rule: No accounts. No watermarks. No "waiting in line" for a server. You open the page, drop your images, and the work happens instantly.
Scaling the Browser: Multi-Threaded Concurrency with Web Workers
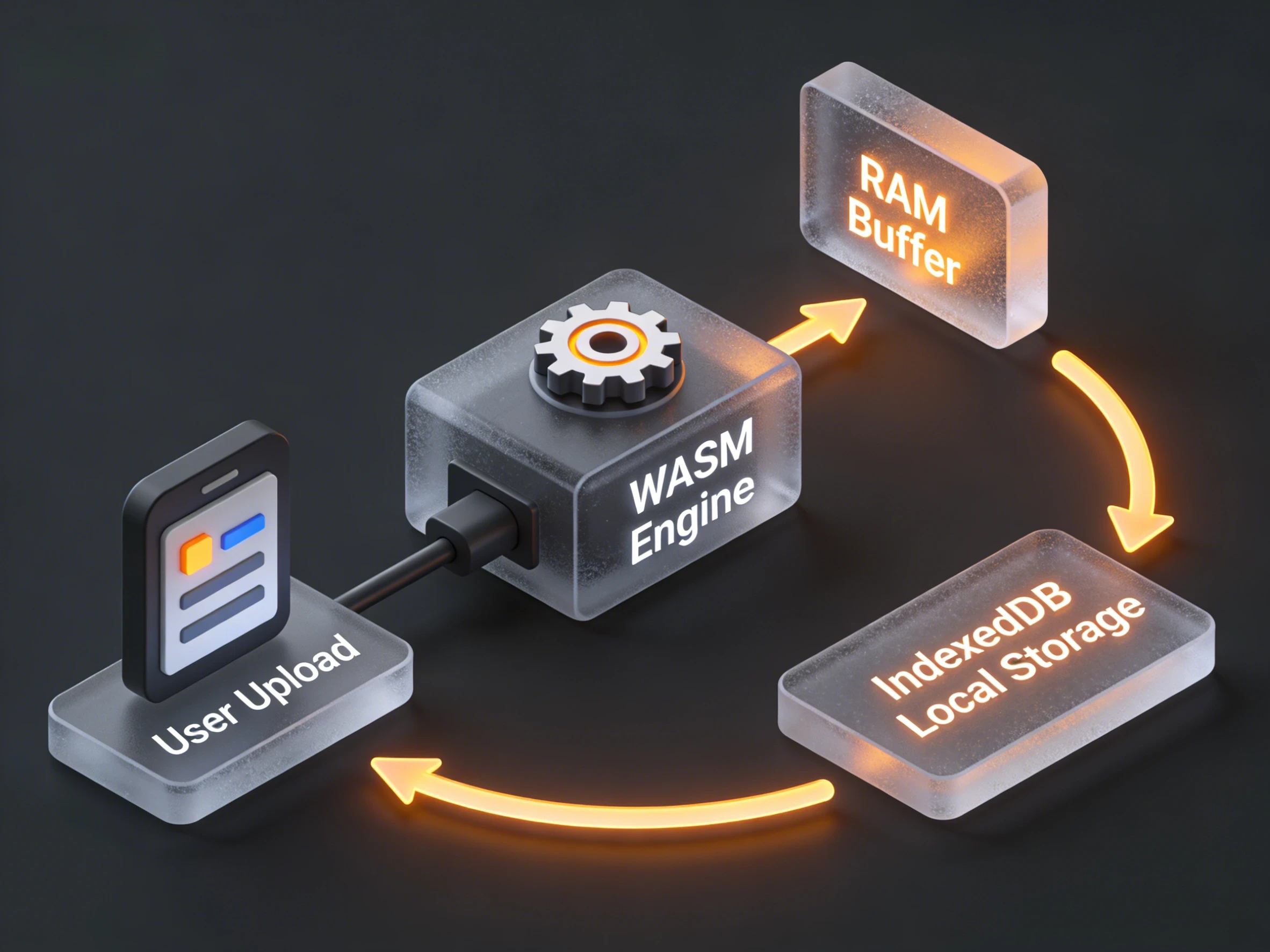
In a traditional single-threaded web app, long-running image processing tasks block the "Main Thread." This results in a frozen UI, where buttons don't click and animations stutter. To solve this, we implemented a Worker Pool Strategy.
The Worker Racing Model & IndexedDB Sync
Instead of a single worker, we spawn multiple Web Workers based on your hardware’s logical core count (e.g., navigator.hardwareConcurrency). These workers compete for tasks in a centralized queue managed via IndexedDB.
The architecture works as follows:
- Dispatcher: The main thread populates an IndexedDB store with raw image metadata and "Pending" status.
- Race Condition Management: Each Worker queries the database for the next available task. We use IndexedDB transactions to ensure that no two workers grab the same image (Atomic locking).
- In-place Processing: The Worker fetches the Blob from IndexedDB, passes it to the WASM module, and writes the transformed result (e.g., the resized WebP) back to a "Completed" store in IndexedDB.
This "Racing" model ensures that even if one image is massive (say, a 100MB TIFF) and takes longer, other workers can keep churning through smaller JPEGs. The result? Total CPU utilization without a single frame drop on the UI.
The Engineering Challenge: Memory Pressure and Blob URLs
One thing we learned the hard way in 2025 was the "Blob Leak." Browsers are notorious for not reclaiming memory from URL.createObjectURL until the document is unloaded. When processing 500 images in a pipeline, this can lead to a massive memory footprint.
By using IndexedDB, we treat the browser's disk space as a "Virtual Swap File."
- We only keep the currently processing images in RAM.
- Everything else—sources, intermediate pipeline steps, and final results—sits safely in IndexedDB.
- We only generate a temporary Blob URL when the user actually clicks "Download."
This is the secret behind why BulkPicTools can handle professional-grade batch jobs that would crash most "premium" online converters.
The IndexedDB Engine: Solving the Memory Bottleneck
If you’ve ever tried to batch process 500 high-resolution JPEGs in a standard web app, you’ve likely seen the browser tab crash with an "Out of Memory" (OOM) error. This is where most client-side tools fail.
At BulkPicTools, we solved this by utilizing IndexedDB as a high-speed, local data bus. Instead of keeping thousands of massive image Blobs in the active RAM (which is volatile and limited), we stream processed data into a persistent local database.
The Persistence Architecture: Why IndexedDB is Our "Virtual Swap"
While most online resizers rely on a transient state, BulkPicTools treats the browser as a persistent workstation. The cornerstone of this capability is our custom IndexedDB Service.
For the geeks reading this, here is a look at how we manage binary data without flooding the JS Heap:
/**
* IndexedDB Service for BulkPicTools
* Used for persisting processed Blob data locally.
*/
const DB_NAME = 'LocalBatchDB';
const DB_VERSION = 1;
const STORE_NAME = 'processedFiles';
class IndexedDBService {
private db: IDBDatabase | null = null;
async init(): Promise<IDBDatabase> {
if (this.db) return this.db;
return new Promise((resolve, reject) => {
const request = indexedDB.open(DB_NAME, DB_VERSION);
request.onsuccess = () => {
this.db = request.result;
resolve(this.db);
};
request.onupgradeneeded = (event: IDBVersionChangeEvent) => {
const db = (event.target as IDBOpenDBRequest).result;
if (!db.objectStoreNames.contains(STORE_NAME)) {
const objectStore = db.createObjectStore(STORE_NAME, { keyPath: 'sessionId' });
objectStore.createIndex('timestamp', 'timestamp', { unique: false });
}
};
});
}
async saveResults(data: SaveResultsData): Promise<string> {
await this.init();
const transaction = this.db!.transaction([STORE_NAME], 'readwrite');
const store = transaction.objectStore(STORE_NAME);
const record: ProcessedFileRecord = {
sessionId: data.sessionId,
blobs: data.blobs,
filenames: data.filenames,
items: data.items,
timestamp: Date.now()
};
return new Promise((resolve, reject) => {
const request = store.put(record);
request.onsuccess = () => resolve(data.sessionId);
request.onerror = () => reject(request.error);
});
}
}
export default new IndexedDBService();
Why this beats the standard "Blob URL" approach
In a standard app, URL.createObjectURL keeps memory locked until the page unloads. When batching 500 photos, this is a memory leak disaster. By implementing the service above, we create a Client-side Virtual Swap File. We stream the heavy lifting into IndexedDB, keeping the active RAM usage lean and the UI buttery smooth even on low-end hardware.
The Recursive Pipeline: Result-as-Source
Now, here is where it gets interesting for power users. Because we have a sessionId mapped to blobs in our database, we can implement Recursive Processing.
In Bulk Image Editor, the sessionId stays active. When you switch "Modules" (e.g., from Resize to Convert), our engine doesn't ask for a new upload. It calls getResults(previousSessionId), pulls the Blobs directly from IndexedDB, and feeds them back into the WebAssembly (WASM) pipeline.
This "Zero-Friction Pipe" is only possible because we moved the data management layer from the JS Heap to the IndexedDB disk layer. You can stack operations—Resize, Crop, Watermark, and Strip EXIF—into a single execution chain with zero network overhead.
WebAssembly: Native Performance in a Nuxt Wrapper
The "Brains" of our engine is written in C++ and Rust, compiled into WebAssembly (WASM). Nuxt (specifically in SSG mode) provides the perfect delivery vehicle. Our site loads as a collection of lightning-fast static assets. Once the hydration happens, the WASM module is loaded into a Web Worker Pool.
Scaling with Multi-Threaded Concurrency
Instead of a single worker, we spawn multiple Web Workers based on navigator.hardwareConcurrency. They compete for tasks in a centralized queue. This "Racing" model ensures that even if one image is a massive 100MB TIFF, other workers keep churning through smaller JPEGs. The result? Total CPU utilization without a single frame drop on the UI.
Memory Management and Auto-Cleanup
A common concern: "Will this fill up my hard drive?" No. We hate "zombie data" as much as you do. Our cleanupExpired() method scans the timestamp index and wipes any data older than 24 hours. This ensures your browser remains clean while giving you a 24-hour "safety net" should you need to re-download your assets.
async cleanupExpired(): Promise<void> {
const expiryTime = Date.now() - 24 * 60 * 60 * 1000;
const index = store.index('timestamp');
// Atomic cursor cleanup...
}
The Nuxt SSG Advantage: Why Static is Faster
You might wonder why a complex image suite is built on Nuxt SSG. The philosophy is Zero Server Latency. By pre-rendering the UI as static HTML, we ensure the Largest Contentful Paint (LCP) happens in milliseconds. There is no server-side logic waiting to execute. The server is just the Delivery Truck, and your browser is the Factory.
Privacy as a Technical Constraint
Most "Privacy First" tools are just a promise in a footer. For us, privacy is a technical constraint of the No-Server architecture. Look at the IndexedDBService code—there isn't a single fetch() or POST call directed at a remote server. We physically cannot see your images. In 2026, keeping your assets in a local IndexedDB sandbox is the only way to ensure your intellectual property remains yours.
Benchmarking the Future: Local vs. Cloud

| Metric | Cloud API (1Gbps Fiber) | BulkPicTools (Local WASM) |
|---|---|---|
| Initial Upload | 8.2s | 0.0s (Instant) |
| Processing Time | 4.5s | 5.1s |
| Download Time | 7.8s | 0.0s (Instant) |
| Total Latency | 20.5s | 5.1s |
The "Network Tax" is a relic of an era when our computers were weak. Today, your smartphone has more processing power than the servers that sent people to the moon.
Final Verdict: The Future is Client-side
The data is clear. By utilizing WebAssembly for raw power and IndexedDB for persistence, we've eliminated the two biggest hurdles of the web: Latency and Privacy. BulkPicTools is a blueprint for a decentralized, high-performance web. No accounts, no uploads, no compromises. Just pure, raw, local speed.
👉 Ready to test the pipeline? Head over to our Bulk Image Editor and try processing 100 images. Watch your DevTools 'Network' tab. You won't see a single byte leave your machine. That’s the power of the No-Server revolution.
Have questions or feedback? Contact